

Protein engineering is a field primed for artificial intelligence research. Each protein is made up of amino acids; to optimize a protein function, researchers modify proteins by switching out one of 20 different amino acids for another. For a protein that is just 50 amino acids in length, this leads to approximately 1.13x1065 potential combinations to test — that’s 113 followed by 65 zeros, or five times as many zeros as a trillion has.
This number of potential combinations, impossible to test in the lab, makes protein engineering an ideal challenge for AI. Modeling which of these combinations will give the best results is a perfect problem for the technology’s massive computing power. But AI is only as good as the data used to train it, and in some areas of protein engineering, the right data just didn’t exist.

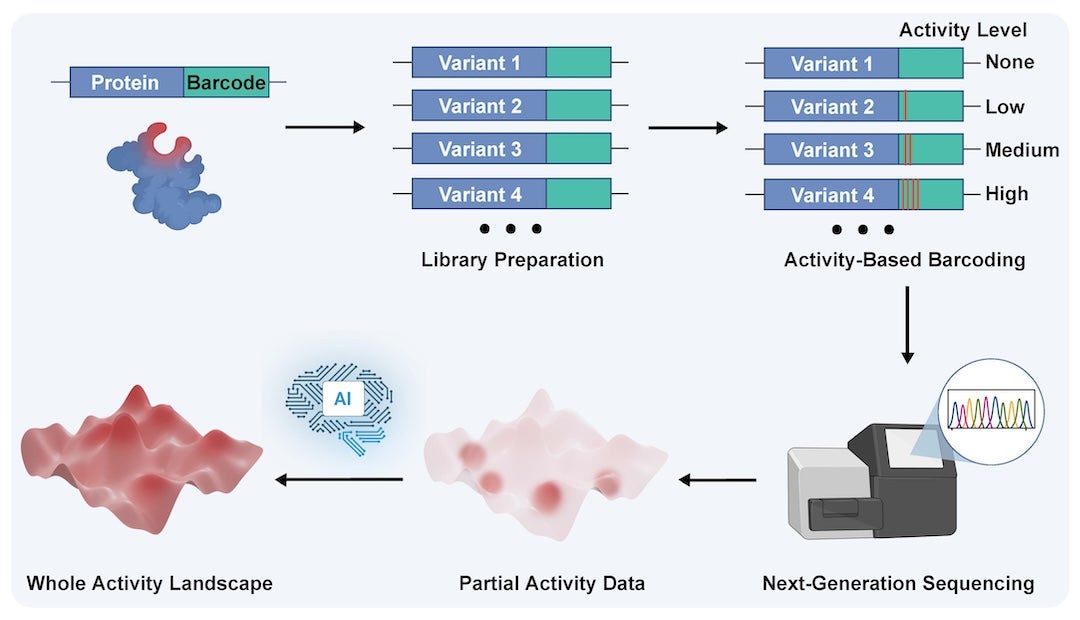
“One of the biggest bottlenecks in AI-guided protein engineering is not coming up with machine-learning models. It is generating the right and enough experimental data to train them,” said Han Xiao, Rice University professor of chemistry, biosciences and bioengineering and director of the SynthX Center. “For engineering protein activity, which optimizes what a protein does, we had a very clear problem: There simply were not enough datasets to train accurate models.”
To be able to generate AI models that could accurately predict how to optimize a protein’s function, or activity, Xiao’s team had to first generate enough activity data about any given protein to train an AI model. In a recent Nature Biotechnology publication, Xiao’s team and collaborators from Johns Hopkins University and Microsoft did just that, sharing an approach that provided the needed data and created accurate models in just three days.
This approach, called Sequence Display, can generate more than 10 million data points in a single experiment. These data points are then fed into protein language AI models, which use them to predict which changes to a protein’s amino acids will create the desired change for the protein’s activity or function.
“We were able to develop an activity-based barcoding system that records the activity of individual protein variants and generates the kind of dataset needed to train a machine learning model,” said Linqi Cheng, a Rice graduate student and first author on the study. “Then the model was able to predict mutations that significantly improved the activity of the protein we were studying.”
The team chose a small CRISPR-Cas protein for proof of concept. This protein was valued for its size but limited in its activity to target stretches of DNA to cut. The researchers wanted to identify a version that could cut a wider variety of DNA targets.
First, they mutated the DNA that codes for the Cas9 protein, creating many variations. A blank DNA barcode was attached to each variant, along with a special editor that would change the barcode in response to the protein’s activity level. As the protein’s activity levels increased, so did the editor’s. This meant that the most active protein variations had the biggest changes in their barcodes. The DNA barcodes were then read by next-generation sequencing, which would essentially scan the barcode and classify each sequence by level of activity.
“The AI is not replacing the experiment here. It instead depends on the experiment,” Cheng said. “Sequence Display gives us the data foundation, and the models help us search a much larger data space for strong candidates.”
The team successfully repeated this process with other proteins, including aminoacyl-tRNA synthetases, cytosine deaminase and uracil glycosylase inhibitor. In each case, the barcoding experiment generated enough data points to train AI models.
“What this approach provides is a practical framework for integrating AI with protein engineering,” said Xiao, who is also a Cancer Prevention and Research Institute Scholar. “Rather than relying on machine learning as a stand-alone solution, we couple it with an experimental platform that generates high-quality training data. This synergy enables more efficient discovery of advanced research tools and next-generation therapeutic proteins.”
This work was supported by a SynthX Seed Award (SYN-IN-2024-002), the National Institutes of Health (R35-GM133706, R01-CA277838, R01-AI165079 to H.X.), the Robert A. Welch Foundation (C-1970 to H.X.), the U.S. Department of Defense (W81XWH-21-1-0789, HT9425-23-1-0494, HT9425-25-1-0021 to H.X.), a 2024 Rice Synthetic Biology Institute Seed Grant (H.X.) and a Medical Research Award from the Robert J. Kleberg, Jr. and Helen C. Kleberg Foundation.